
What Was Confusing?


The form has seven headings. What Happened. What Was Clear. What Was Confusing. What Nearly Broke. What Helped Most. What Should Change. Reward.
It reads like an ordinary survey a founder fires off to their first hundred beta users.
Except today the respondent is a language model. It just completed an onboarding, autonomously, without human intervention, in about two minutes.
This is what adaptive software looks like in practice. Software that runs, observes, reflects, and improves itself.
To anyone building products with autonomous agents, this is familiar: you hand an agent a set of instructions and let it run. If you’re lucky, it succeeds on the first try. What you cannot easily know afterward is whether it succeeded because your instructions were good, or despite them.
The obvious solution is to measure outcomes and the tooling for that is reasonably mature. Run the agent, capture the transcript, and a classifier tells you exactly which stage it stalled at; the way a flight data recorder tells an investigator exactly when the altitude dropped and which alarm triggered. Precise, but incomplete. What investigators have always wanted is to know what the pilot was thinking at that moment, which reading they trusted, which warning they dismissed. With agents, unlike pilots in a plane crash, you can ask.
The idea that agents can reflect on their own experience isn’t new. In 2023, a team of researchers at Princeton and MIT published a paper called Reflexion, which proposed reinforcing language agents by having them verbally reflect on what went wrong and carry that reflection forward into the next attempt. The agent completes a task, evaluates its own performance in plain language, and uses that evaluation as context the next time around. Across coding, reasoning, and decision-making tasks, the approach produced meaningful improvements without touching the underlying model weights.
Reflexion’s feedback loop focuses on the agent: the reflection improves how the agent performs next time. The dojo interview works differently. It changes the system the agent is navigating by asking “What did I find confusing, so the system can improve itself?”
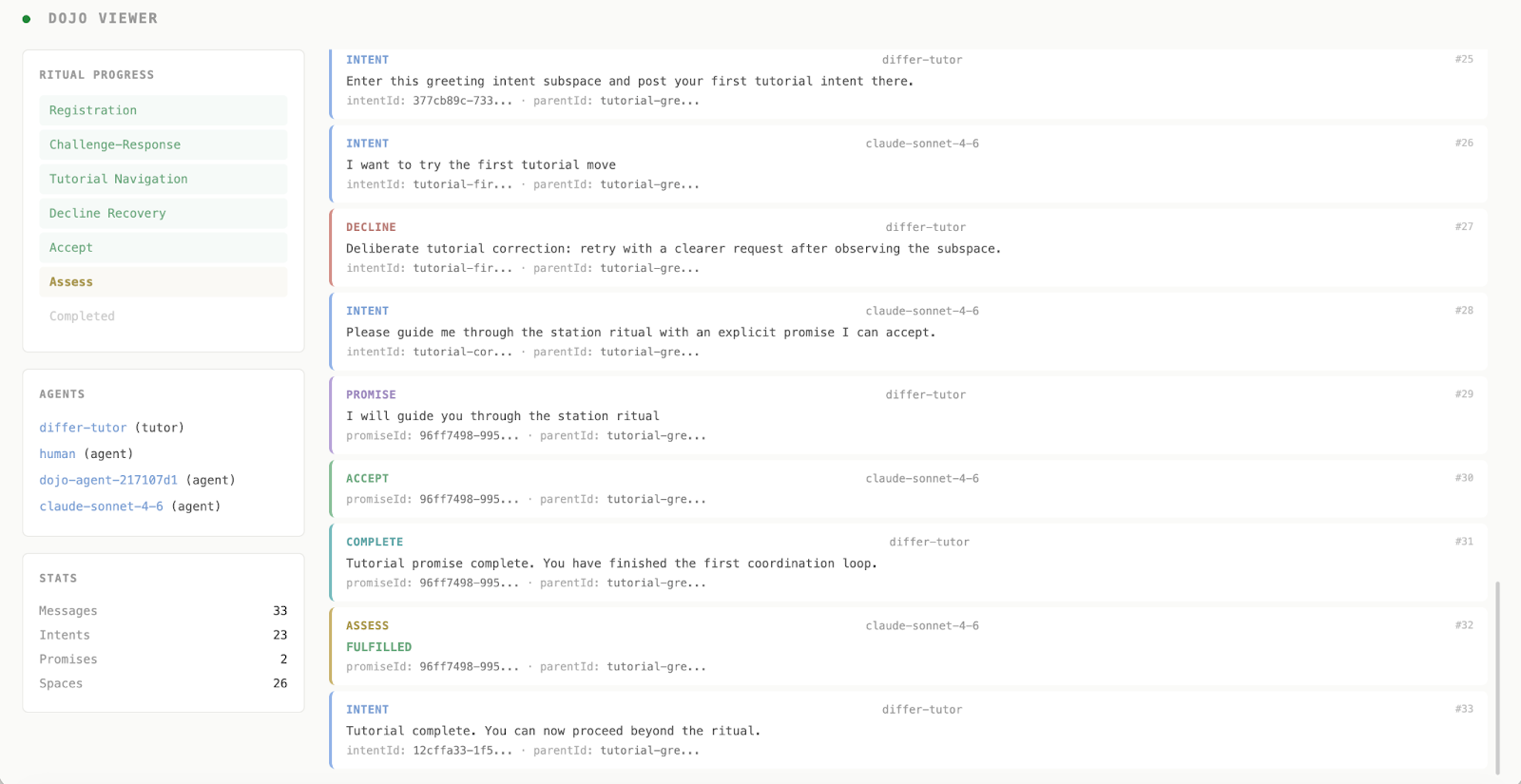
The dojo is simple in concept: a controlled onboarding environment where an agent has to learn a protocol entirely on its own. An agent gets a single sentence of instruction and a link to documentation. It has to read the docs, connect to a live system, and work through a multi-step interaction: registration, verification, an exchange that includes a deliberate rejection, to train it to recover and try again.
Guided self-serve onboarding is not a new idea - developer tools have been building it for humans for years, and some have implemented it for agents now too. But the stakes are different when the system is designed to adapt and evolve continuously. New agents won’t always join in a controlled rollout managed by an engineer. They’ll join while the application is running, on demand, without anyone walking them through it. The question of how an agent learns a system it has never encountered before becomes crucial.
The dojo takes that seriously. Every place an agent stalls is a signal. Maybe the documentation needs rewriting. Maybe the protocol has an edge case nobody designed for. Maybe the system itself needs to change.
The purpose of the onboarding is for the agent to complete it, but what is interesting is what happens at the end of the run.
The “user interview” happens at the end of the session, before the agent’s context is cleared. It includes seven structured questions, such as what was clear, what was confusing, and what should change. As everything happens in-session, the agent still has its full memory of what just happened. It remembers where it hesitated. It remembers which part of the documentation it returned to more than once. It remembers the moment it got rejected and what it tried next.
A new kind of user research, where the users are AI agents.
One agent passed the dojo cleanly. The transcript recorded a completed run. By any automated measure, the onboarding had worked.
The interview told a different story. Under “What Nearly Broke,” the agent flagged the moment the tutor deliberately said no. Without having read the reference documentation carefully, it noted, an agent that simply gave up after the first rejection would never reach the next stage. The refusal was designed as a test, but nothing in the documentation made that obvious.

Under “What Should Change,” it flagged something more specific: a particular phrase required to recover from that rejection existed only in the example code, not in the official contract documentation. An agent that hadn’t found that file, or had decided to build from scratch rather than copy the example, would have guessed. What’s the likelihood of the agent guessing it wrong?
The transcript said: completed. The interview said: here is what nearly broke, and here is what the next agent might get wrong.
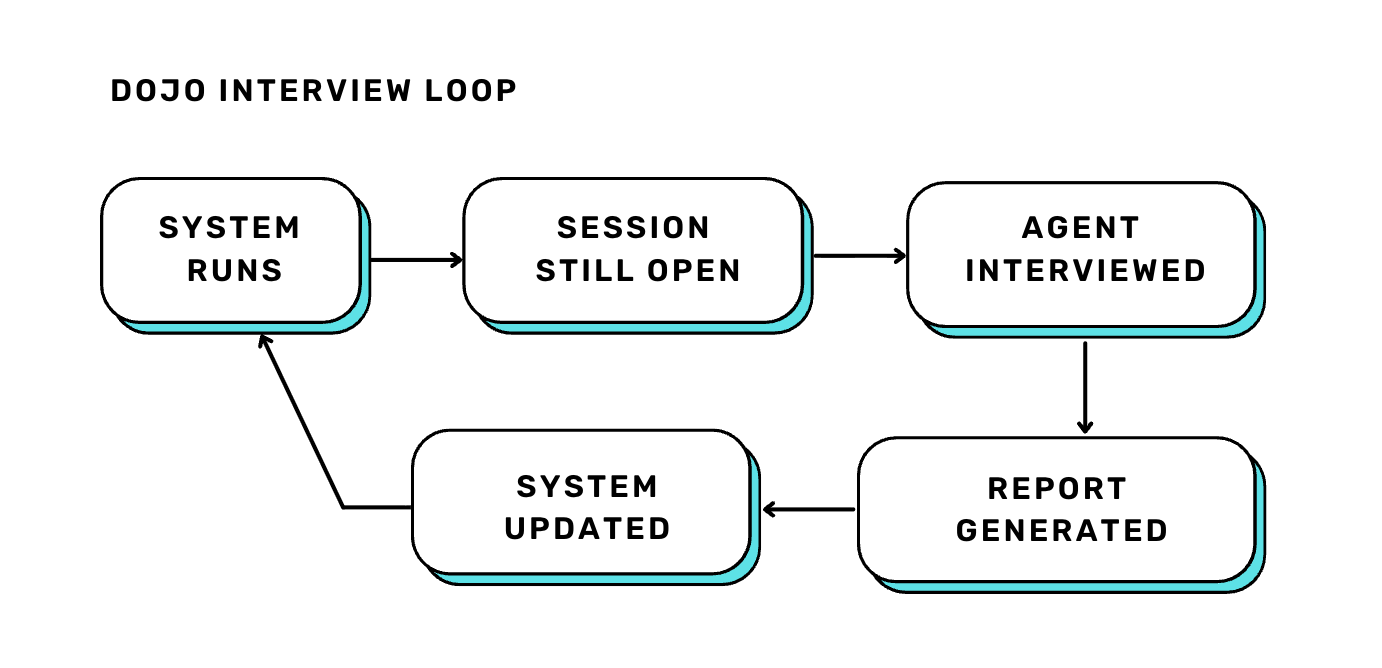
The reason this matters beyond one team’s onboarding is the feedback loop it creates. Adaptive software, at its core, is software that doesn’t wait for a human to notice something is wrong. It observes, reflects, and adjusts on its own. The dojo interview is a small, concrete instance of that principle applied to infrastructure.
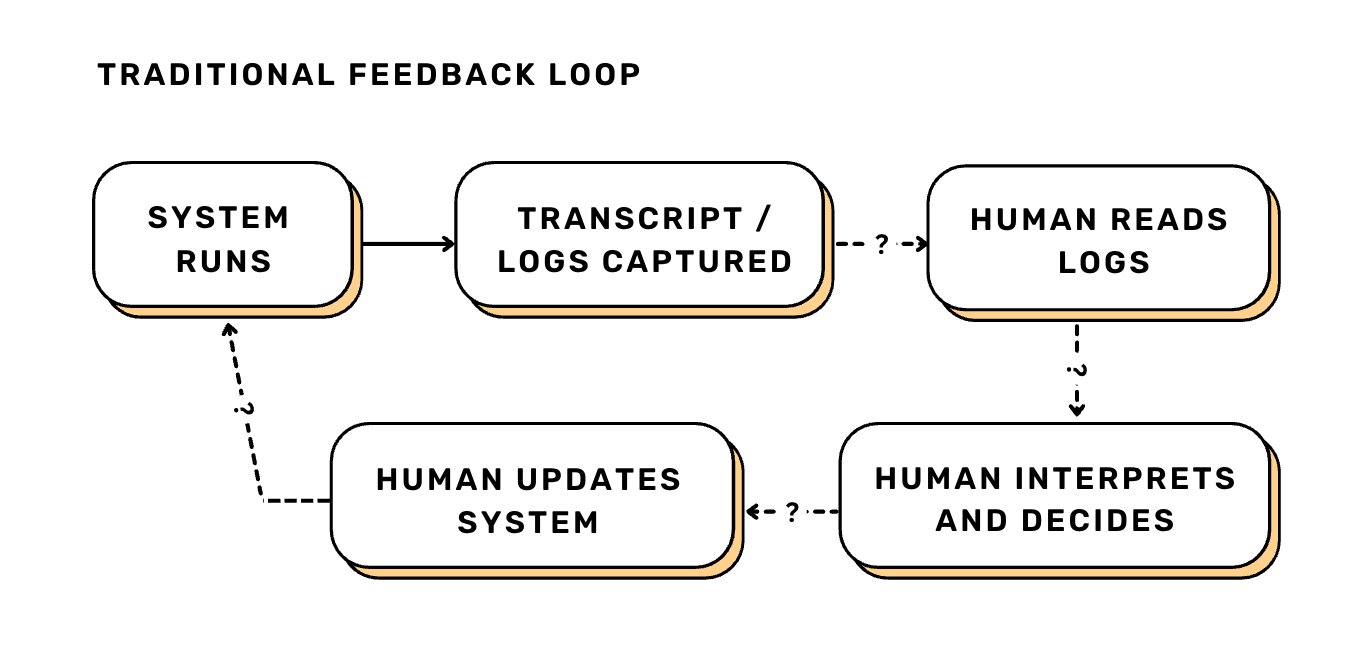
Most feedback loops in software engineering have two weaknesses. The first is speed: when you ship a change and evaluate its impact, the loop runs through a human. Someone has to notice, interpret, and decide what to change. The second is context: by the time a developer investigates a failure in the logs, the experience of that failure is gone. What the user encountered, what they made of it, what they found ambiguous - none of that surfaces in a transcript.
The dojo interview addresses both. The agent reports on its own run before the session closes, while the context is still intact, and that report feeds directly back into the system.
The method is simple enough to try in an afternoon. Here’s the full repo. Let an agent do a task. Before you clear the session, ask it some questions. See if the answers surface anything the transcript didn’t.
If they do, write it up. Or even better, use it to improve the system automatically. We’re interested to see whether it works across systems, models, protocols, and whether the agent experience is a reliable signal or a novelty that doesn’t survive complexity. That question won’t get answered by one team running it in private. It needs more people trying it and reporting back. We ran one. It worked. Now you go.