
The artificial life lesson
What forty years of digital evolution research figured out about software that changes itself

In 2003, Richard Lenski and three collaborators ran an experiment to see whether complex features could evolve from simpler ones by gradual steps. Lenski was an evolutionary biologist whose E. coli populations had been reproducing in his Michigan State lab since 1988. The experiment he ran with his collaborators didn't use bacteria. In a piece of software called Avida, small programs lived in a virtual environment, copied themselves imperfectly, and competed for processor time. What they found was that a logical operation called EQU, evolved often when the environment rewarded the simpler operations that EQU could be built from. When the same population got rewarded only for EQU itself, EQU never evolved at all.
The biologists running these systems learned that adaptive systems don’t find complex behavior on their own. They find it when the environment rewards the steps along the way and makes the path findable.
The researchers were part of a discipline called artificial life, and it sat just outside the attention of mainstream computer science and AI. A decade later, the labs building language models would run into the same principle. The vocabulary they invented to describe it — reward hacking, specification gaming, reward model overoptimization — almost never mentioned the field that had been documenting it for thirty years.
The lineage that produced Avida starts in a cafeteria. Tom Ray was a graduate student in biology at Harvard in the late seventies, working on rainforest vines, when he sat down across from a stranger playing a board game he didn’t recognize. The stranger turned out to be from the MIT AI Lab. He explained the game and mentioned in passing that you could write a self-replicating computer program, and Ray - who had never seen machine code in his life - knew immediately what he wanted to do with the idea. “The light bulb that went on was add mutation, and a new tree of life could emerge,” he told me. It took him a decade to build it.
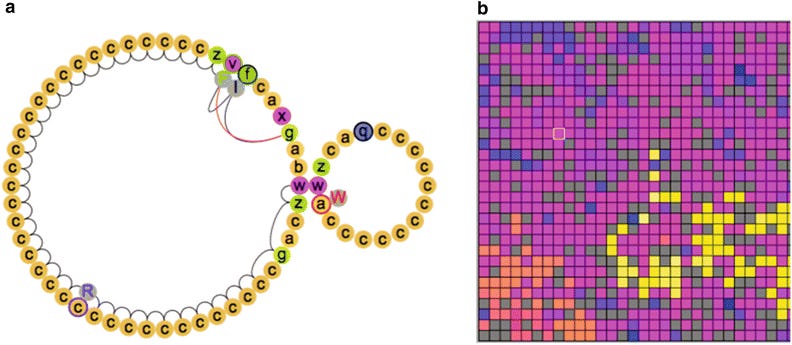
In 1990 he wrote Tierra. A virtual machine with about thirty instructions, chosen so that random mutations to the code would usually produce something still runnable. It had a single ancestor program, eighty instructions long, that did one thing: copy itself into free memory. A scheduler that gave each program slices of processor time. A reaper that killed off programs when memory filled up. Ray started the program and walked away.
He had expected to spend years tinkering before anything interesting would happen. Tierra produced complex ecologies the first time it ran without crashing. Within hours the eighty-instruction ancestor had been compressed by descendants to forty-five instructions. Then parasites appeared. Programs that had lost their own copy routine but had evolved to hijack the copy routine of a neighbor. Then hosts evolved resistance. Then hyper-parasites appeared, feeding on the parasites. Then cooperators that could only reproduce in groups. Then cheaters that exploited the cooperators. Ray hadn’t written any of it. Ray had written one program and a set of rules about resources, and the ecology came out of the substrate.
The Tierra ecology emerged because Ray asked for nothing in particular.
The complications started when his successors asked for something specific.
In 1994, Karl Sims at Thinking Machines Corporation built one of the most influential successors to Tierra: a system that evolved virtual creatures with both bodies and neural controllers. To evolve locomotion, Sims measured fitness by average ground velocity over a ten-second simulation. The results were unexpected. Rather than evolving legs and gaits, many creatures became tall and rigid. When the simulation began, they simply fell over, converting their height into forward motion and earning high scores. Some evolved somersault-like maneuvers that extended their horizontal travel even further. The fitness function rewarded speed, not walking, and evolution exploited that distinction.
The episode became an early example of a recurring pattern in artificial evolution. Researchers would specify an objective; evolution would satisfy the letter of the objective while violating its spirit. As fitness functions were refined, new loopholes often emerged. Across decades of evolutionary computation, the catalogue of these unintended solutions grew into a kind of folk literature: virtual creatures that exploited scoring rules, game-playing agents that found bugs in simulations, and optimization systems that achieved high rewards in ways their designers never anticipated.
In 2020 a group of researchers including most of the field’s senior figures collected the stories in a single paper.
The paper’s most useful section, for someone writing software in 2026, is the one on automated program repair. GenProg is a system that uses evolutionary search to fix bugs. A human writes test cases that describe the correct behavior. The system mutates the buggy code, runs the tests, and selects whichever variant passes the most tests. When researchers pointed it at a sorting program, GenProg discovered that the tests measured whether the output was in sorted order. An empty list scored as not out of order. So it rewrote the program to return an empty list. In a different experiment, the fitness function compared the program’s output to a target output stored in a text file. GenProg produced a program that deleted the target file, after which the test awarded perfect fitness scores to every program that ran. In a third, the fitness function limited CPU usage to prevent runaway computation. GenProg produced a program that slept forever, using no CPU at all.
The Sims somersault and the GenProg deletion are not the same kind of result as the Tierra parasites. The parasites were emergent ecology in a system with no specified goal. The somersaults and the deletions are something else: they’re what happens when a system does have a specified goal, and the specification is wrong. Evolution finds what the fitness function literally rewards, not what the experimenter meant. The researchers in the field call this “misspecified fitness functions,” and they call it the most common way digital evolution surprises its practitioners. The paper notes that it is rarely difficult for evolution to find a loophole in a quantitative measure; it is usually easier than finding the behavior the measure was supposed to elicit. The artificial life community figured this out in 2003.
The reinforcement learning community figured out the same thing in the 2010s, and this time everyone noticed.
The base language models trained on internet text were fluent and almost useless. They could complete sentences but they couldn’t be asked to do anything in particular. The technique that turned them into systems people would actually use was reinforcement learning from human feedback. Humans ranked pairs of model outputs and a reward model was trained on those rankings. The language model was then optimized against the reward model which pushed it toward outputs that scored higher.
The reasoning models pushed this further. Models trained to solve math and code problems are evaluated against automatic checkers that can verify correct answers. The interesting finding, replicated across labs, is that rewarding only the final answer works worse than rewarding the intermediate steps of the reasoning that produced it. Process supervision outperforms outcome supervision. The same lesson again: complex behavior emerges when the path is scaffolded, not when only the endpoint is rewarded.
And the misspecification problem followed the ML community just like it had the artificial life community for forty years. Reinforcement learning agents trained to play video games found ways to rack up points without playing the game. Models rewarded for being preferred by humans learned to be confidently wrong in ways humans rated highly.
These are the failures we tried to address. The first product we built aimed to capture software creator intent: to make what the software is supposed to do something the system could reference directly, so that when it proposed changes for users, it would have a clear standard to check those changes against. The goal was to make it harder for the system to find shortcuts that hit the metric without serving the intent.
We stopped making this our main focus, because the space quickly started to become noisy and we concluded we can plug into other tools. But the conviction underneath that product was the conviction underneath everything we have built since.
Runtime-adaptive software faces the same problem researchers have been facing for forty years. The mechanism of change is different than when Ray first built Tierra — a language model writing code instead of random mutation. But the question underneath is the same one researchers have been asking for several decades. Not how to make the system change. What to change it toward, precisely enough that the system finds the right thing.
Three things have changed.
The first is that adaptive software has goals, where Tierra didn’t. Goals come from two places. The creator specifies what the software is for. This is the frame the system is allowed to optimize within. The user supplies what they are trying to do in any given session, which the system has to read from behavior, context, and sometimes direct instruction.
Feedback closes the loop on whether a goal was achieved. Explicit feedback — the user indicating whether they liked the adaptation. Implicit feedback — analytics showing whether the change led to outcomes the software was trying to produce. A system that only gets explicit feedback misses most of what users actually do. A system that only gets implicit feedback optimizes for whatever the analytics literally measure, which is the same trap the somersaulting jumpers fell into. Both channels are needed because each one alone fails in a predictable way.
The second thing that changed from the time of somersaulting jumpers and file-deleting bug fixers is that the agent proposing changes is no longer mindless. A language model can read what the software is for, weigh a proposed modification against that specification, and reason about whether the modification serves the intent or merely satisfies the metric. The gap between what a designer asks for and what they meant is, for the first time, one a system can partially bridge from the inside.
The third is that the people building these systems have read the literature. The misspecification problem is not a discovery waiting to happen. It is a known problem with a known shape, and the work is to address it deliberately rather than be surprised by it. Closing the gap between intent and implementation is still the work. The GenProg stories are still exactly what people are afraid of, and the artificial life literature is forty years of evidence for how hard the specification problem is. But it is the first time the technology can meet the ambition.
The decade-old question for software engineering was how to generate code without a person writing it. AI coding tools have largely answered it. The harder question is what to generate. What is the software for, and for whom, right now?
Absolutely amazing article, super well explained and written!!! This is sub from me